Open Source Accelerated Deep Learning
Harley Wiltzer, December 2020
In 2016, following the first year of my undergrad, I built a PC. I try to use open source software, particularly free open source software ("free" as in "freedom", not as in beer, of course), so naturally I bought a fancy new AMD Radeon RX480 GPU. This was also around the time that the open source AMDGPU drivers were gaining some popularity among the Linux community, as performance was beginning to rival that of the properietary NVidia drivers. Then a little while later I became fascinated by machine learning and had to face the hard "reality" that NVidia's CUDA, supported by the canonical deep learning frameworks, leads to massive performance gains for tensor computations often used in deep learning. Since CUDA is only compatible with NVidia cards, I began to wonder if my Radeon card was an expensive mistake.
Thankfully, this turned out to not be the case. In fact, I'm more proud of my Radeon purchase now than I ever was. I very recently learned about the open source ROCm (Radeon Open Compute) software by AMD that provides GPU acceleration for such tensor computations with AMD cards, as well as some other neat tools that help unify acceleration for various GPU architectures, which I believe the deep learning community can make great use of. I had head of ROCm a few years ago, but it appeared back then that ROCm wasn't very functional or robust, so I naively disregarded it. A couple of weeks ago, inspired by a Reddit post, I decided to dive deep into ROCm and I was determined to set it up on my PC.
Building from Source, and a Rant About Package Managers
Installing ROCm is… challenging. I don't mean to blame the developers, ROCm is an extremely complex project with many, many distinct components that interact with each other, and this naturally causes build challenges. Especially given that this is all being provided for free, a challenging build is a price that I'm willing to pay. What's less acceptable to me, however, is the absurdity of AMD's documentation for the installation of ROCm. Again, ROCm is composed of a plethora of distinct packages, so one would expect there to be a coherent build guide, or even just a diagram to show dependencies, but it's much, much worse than that. AMD only provides support for Ubuntu/Debian, so the only actual guides revolve around building Ubuntu Docker containers that source ROCm binaries from AMD's repository. This is disgusting.
The Rant about Package Managers
Some years ago, I was pointed to this wonderful blog post (please
excuse the profanity) by Michael Orlitzky. While it is blatantly
eccentric, this article has since been perpetually at the back of my
mind, because the message it conveys is very bold, makes some great
points, and is portrayed in a humorous manner. The idea is that people
tend to be too afraid and/or too lazy to either build or use proper
package managers. For instance, the trend these days it to make
language-specific package managers (pip, cargo, cabal, node,
…), platform-dependent package managers (apt), and package
managers that only know how to handle binaries (apt, pacman). And
this is all garbage, especially the first two categories. With
language-specific package managers, users end up with a boatload of
disjoint package managers that they almost surely are not keeping up
to date, and by construction they do not cohesively manage
dependencies. Consequently people use things like virtualenv and
conda, which basically says "rather than worry about dependencies,
why not just put each project in an isolated box with its own
dependencies". This is stupid because now you have several copies of
all these dependencies and you're still not managing dependencies
properly, in fact you're neglecting the issue of dependency hell
altogether. And Docker containers are basically the same idea, but
rather than bundling some python code with some libraries, it's an
improvement since it bundles an entire operating system! Let me make
it very clear that the previous sentence was sarcastic, because this
is an absolutely atrocious idea for similar reasons (for the record, I
recognize that Docker does make sense in some settings, it just
doesn't make any sense to depend on it for projects you're building on
your PC).
The author's suggested solution is pretty bold. He claims (correctly)
that the Gentoo Linux package manager, portage, satisfies all of the
desired properties of package managers. Moreover, since it's
cross-platform, he says every software developer should distribute
software for portage. Note that the author is a Gentoo developer, so
there is clearly some bias. But the more I think about it, the more it
starts to make sense to me. And my journey to install ROCm only
cemented this idea further.
The Need to Build from Source
So in the previous section, I mentioned how the ability for a package manager to build software from source is very desirable. Until I started building software from source frequently, I didn't realize that lots of software is distributed with lots of configurable parameters that actually affect the binary that is produced. For instance, Vim provides a massive selection of features, many of which I have no use for. By configuring the build, I can choose to simply not build in these features, resulting in a more lightweight binary. More severely, building ROCm (and the PyTorch with ROCm support) allow you to configure the build depending on your GPU architecture. Quoting Michael Orlitzky's article, by simply downloading a binary package, you are assuming that whoever built it for you has to
- know that your architecture exists; and
- give a s*** about you; and
- find a computer like yours to test it
Usually one of these criteria is not met (guess which one).
Indeed, at least one of these criteria was not met when I tried ROCm with those pre-built Docker containers, as the ROCm system was built without support for my GPU. Also containers suck, as I explained before, so I set out to build ROCm myself. However, since it's expected that everyone will use pre-made containers, very little effort was made to make the process of building from source a smooth one.
Install Gentoo
So what's the solution to this problem? Michael Orlitzky suggests that
all software developers should distribute software as ebuilds, which
are essentially shell scripts that tell Gentoo's package manager
portage how to configure the source, build the software, and manage
its dependencies. And after this experience, I have to say that I
kinda agree with this notion. I mean, I acknowledge that this is an
unrealistic proposal, but there are some absolutely awesome advantages
to using portage that are just intrinsically great, and I can't
imagine any cogent argument that suggests otherwise. Here's some
reasons why:
portagegoes beyond just managing dependencies, it can even figure out dependency satisfaction due to those build configuration options I described above.- Since the dependencies are managed so nicely, the ebuilds themselves make up a build guide – that is, you don't need any instructions beyond the ebuilds to get the build up and running.
- The Gentoo developers have developed useful standards for implementing a vast array of common operations, which significantly reduces boilerplate and requisite mental capacity.
- The Gentoo developers have also developed automated QA to reinforce good practices. This includes a standard for installing binaries, headers, libraries, and anything else; this alone should substantially reduce build failures.
This list is not comprehensive, by the way.
Thankfully, I've been using Gentoo for a few year already – I didn't
install it for the sole purpose of getting ROCm to work properly and
to write this post. But you don't actually need to install Gentoo to
use portage (it has cross-platform support!), rather, you might
prefer simply using Gentoo Prefix. While this does in fact add a
package manager to your system, it is at least an extremely robust
package manager that can suit all of your needs.
Installing ROCm with Portage
Over the past little while, I've been tweaking ebuilds so I can get a working build of ROCm. This job was made much easier than it could've been, thanks to the very nice set of ebuilds maintained by justXi for ROCm. Unforunately, the versions of ROCm that they maintain are too recent, and they do not support my GPU. Thus, I worked on making functioning ebuilds for an older version (3.5.1), which both supports older GPUs and is supported by Tensorflow and PyTorch. My overlay is available on GitHub if you'd like to follow along.
Installing the ROCm core is done as follows:
- Build the
amd-rocm-metapackage:
$ sudo emerge --ask --verbose "=sci-libs/amd-rocm-meta-3.5.1"
And that's all. Well I guess that's a bit of an exaggeration since you'll need to set up an overlay and perhaps some configuration first, but these tasks just become routine as you get used to Portage. I'll outline the steps explicitly.
1. Set up an overlay
In order for Portage to "register" a third party set of packages (or
ebuilds, more precisely), you'll need to set up an overlay. Gentoo
provides a nice tool called layman to help with this, however I find
it's actually easier to set it up manually. I'll be referring to the
variable ${EPREFIX} to account for a Prefix setup as opposed to an
actual Gentoo system. On Gentoo, ${EPREFIX} simply refers to the
root directory. With that out of the way, let's begin.
Start by cloning my repo and putting it in a nice location. Also make
yourself part of the portage group to make editing ebuilds much
easier.
$ sudo usermod -a -G portage ${LOGNAME}
$ cd ${EPREFIX}/var/db/repos
$ git clone https://github.com/harwiltz/rocm
$ chown -R ${LOGNAME}:portage rocm
[rocm]
location = ${EPREFIX}/var/db/repos/rocm
Now the overlay is ready to go.
2. Configure Portage
I guess this part is optional if you declare the environment variables
manually when installing amd-rocm-meta. But I think this is a nicer
solution.
... HIP_PLATFORM=rocclr MAKEOPTS="-j4"
The MAKEOPTS variable determines how many parallel processes can be
run during the build, people often say to set this to n_cpu_cores +
1. I tend to set it a little lower than that so I can use my machine
while building stuff in the background.
Now, before packages are tested thoroughly they are keyworded by the
CPU architectures for which they're still being tested. We need to
tell Portage to accept these packages. Usually I just run my emerge
commands and update my configuration as it tells me to, because it
could be a little difficult/tedious to figure them all out a
priori. But here's the relevant configuration that works for me.
=sci-libs/pytorch-1.6* ~amd64 =dev-libs/half-2.1.0 ~amd64 =dev-libs/rccl-3.5.0 ~amd64 =dev-libs/rocclr-3.5.0 ~amd64 =dev-libs/rocm-comgr-3.5.0 ~amd64 =dev-libs/rocm-device-libs-3.5.0 ~amd64 =dev-libs/rocm-opencl-runtime-3.5.0 ~amd64 =dev-libs/rocm-smi-lib-3.5.0 ~amd64 =dev-libs/rocr-runtime-3.5.0 ~amd64 =dev-libs/roct-thunk-interface-3.5.0 ~amd64 =dev-util/amd-rocm-meta-3.5.1 ~amd64 =dev-util/rocminfo-3.5.0 ~amd64 =dev-util/rocm-clang-ocl-3.5.0 ~amd64 =dev-util/rocm-cmake-3.5.0 ~amd64 =dev-util/rocm-smi-3.5.0 ~amd64 =dev-util/roctracer-3.5.0 ~amd64 =sci-libs/hipBLAS-3.5.0 ~amd64 =sci-libs/hipCUB-3.5.0 ~amd64 =sci-libs/hipSPARSE-3.5.0 ~amd64 =sci-libs/miopen-3.5.0 ~amd64 =sci-libs/rocFFT-3.5.0 ~amd64 =sci-libs/rocBLAS-3.5.0 ~amd64 =sci-libs/rocPRIM-3.5.1 ~amd64 =sci-libs/rocRAND-3.5.0 ~amd64 =sci-libs/rocSOLVER-3.5.0 ~amd64 =sci-libs/rocSPARSE-3.5.0 ~amd64 =sci-libs/rocThrust-3.5.0 ~amd64 =sys-devel/hcc-3.3.0 ~amd64 # Deprecated, no newer releases =sys-devel/hip-3.5.1 ~amd64 =sys-devel/llvm-roc-3.5.1 ~amd64 dev-python/CppHeaderParser ~amd64
Note that the file above can be named arbitrarily (as long as it's
under ${EPREFIX}/etc/portage/package.accept_keywords).
Finally, if you plan on installing deep learning libraries, I recommend also adding the following,
sci-libs/amd-rocm-meta deeplearning
Like the previous example, this file can be named arbitrarily as long
as it's in the right directory. Here, we are setting the
deeplearning USE flag to the affirmative for the amd-rocm-meta
package, which will activate some more dependencies.
Now we're ready to start the build!
3. Building ROCm
We can now run the command I foreshadowed earlier,
$ sudo emerge -av amd-rocm-meta
When this build completes, you'll be all set to install PyTorch or Tensorflow. I believe these are the only two major ML frameworks that have support for ROCm, although to be honest I haven't looked very far.
Potential build issues
Given the complexity of this system and the intensity of some of the
builds, the build of amd-rocm-meta might not succeed all the way
through on the first go. Thankfully, however, with the state of the
ebuilds at the time I'm writing this post, I only ran into one problem
that occurred on a few of the dependencies. Some of these builds, such
as rocFFT, use lots of memory and compute. I've seen it suggested
from a few sources to have 16G of memory available for the build, and
I don't think that's a conservative estimate. In fact in one of the
ebuilds in justXi's overlay, there is a warning that 28G of memory
should be available. My machine has "only" 16G of memory in total, so
I figured I might be safe (especially given that my Gentoo setup is
very lean on RAM usage). However, occasionally I would run into build
errors that turned out to be due to insufficient memory.
The good news is that, at least in my experience, this problem can actually be mitigated. In particular, if you experience a build error that appears very odd and that you can't explain, it could very well be due to some memory corruption, but you can try the following,
$ sudo MAKEOPTS="-j2" emerge -v1 <package> $ sudo emerge -v amd-rocm-meta
where <package> is the package whose build failed. The "2" in
"-j2" can really be replaced by any number less than the one you
specified in make.conf earlier. Note that it would not behoove you
to run
$ sudo MAKEOPTS="-j2" emerge -v amd-rocm-meta
since I suspect that many dependencies should build successfully with more processes.
4. Testing the ROCm setup
As a quick sanity check, execute the following,
$ ${EPREFIX}/usr/lib/rocm_agent_enumerator
gfx000
gfx803
This should list codes that identify you're GPU architecture. The
gfx000 output corresponds to a CPU, so if that's your only output,
something went wrong.
You can also try running ${EPREFIX}/usr/bin/rocminfo and check if it
lists correct information about your GPU.
Installing Deep Learning Libraries
Assuming everyting above was successful, you should be able to install Tensorflow or PyTorch. I'll go over the PyTorch install since that's my preferred library. However I did quickly test that Tensorflow works with this ROCm setup. For PyTorch, begin by running
$ sudo MAX_JOBS=4 emerge -av "=sci-libs/pytorch-1.6.0-r2::rocm"
The MAX_JOBS variable like before controls how many concurrent
processes can be run, and should be tuned if you get some weird build
failures. If you have a huge amount of memory available, you don't
need to set this variable. Unfortunately, before using PyTorch, you
currently need to manually make some symlinks since the torch module
is hardcoded to look for its shared objects under /usr/lib, which
Gentoo reserves for 32-bit binaries. Portage complains when you try to
install 64-bit binaries there, so the shared objects are installed under
/usr/lib64. So, all we need to do is
$ sudo mkdir -p /usr/lib/python3.7/site-packages/torch
$ sudo ln -s ${EPREFIX}/usr/lib64/python3.7/site-packages/torch/lib \
/usr/lib/python3.7/site-packages/torch/lib
And now we can experience the moment we've all been waiting for:
$ python >>> import torch >>> torch.cuda.is_available() True
You might see some "error messages" that complain about missing files – these files are indeed missing, as AMD has not yet made them open source. However, they are not needed to make good use of your AMD GPU for deep learning. You might also find it odd that it says that CUDA is available even though we're not using CUDA. This is expected behavior – AMD provides a script to translate all CUDA code to HIP, which is an abstraction layer made by AMD that supports both AMD and NVidia backends (isn't this awesome?). Everything is still referred to by CUDA to make it easy to reuse code for the time being.
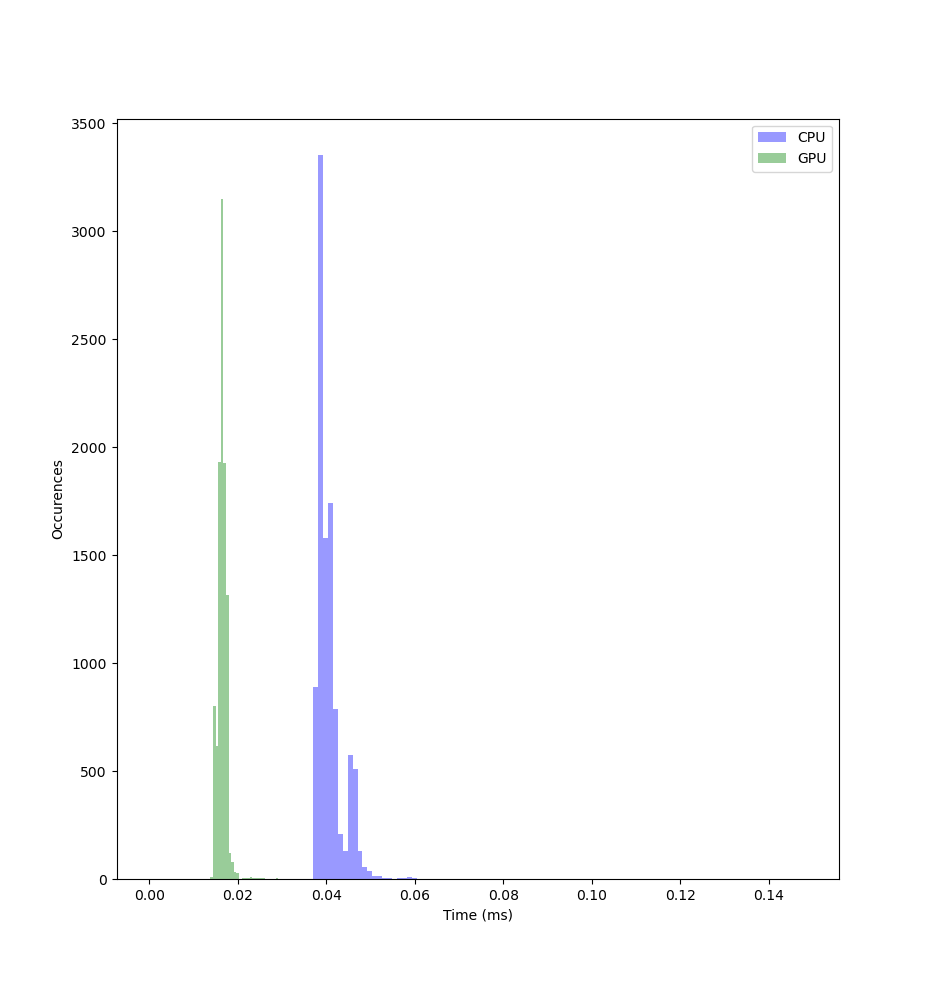
I ran a quick toy benchmark to get an idea of how much faster some computations would be on the GPU. Here's the corresponding (pseudo) code:
import torch # Repeat 10000 times # Record time of matmul for each a = torch.uniform(size=(3, 78, 78)) b = torch.uniform(size=(3, 78, 78)) a_gpu = a.cuda() b_gpu = b.cuda() torch.matmul(a, b) torch.matmul(a_gpu, b_gpu)
The results were convincingly in the GPU's favor:
By the way, the "feature image" for this post depicts Linus Torvalds flipping off NVidia.